We Stand With Ukraine
We Stand With Ukraine 
Big data Framework In The Cloud Computing. Comparing Big Data Frameworks.

In this piece, we will address popular frameworks of big data within the environment of cloud computing and identify some of the attributes of such big data frameworks, as well as touch on some of the biggest hurdles and problems associated with them. This article will categorize resource management big data frameworks by their primary attribute, compare them to other frameworks of a similar nature, and address the recommended best practices associated with their use.
Introduction
While the upside of shifting to cloud computing is well known, the benefits are even more profound in the context of analytics of big data. Inherent to big data is the employment of petabytes (soon to be exabytes and zettabytes) of data. Business analytics requires the use of data-intensive applications, with the scalable nature of the cloud environment being necessary to make their deployment feasible. Leverage of the cloud also promotes easier collaboration and connectivity across an organization, streamlining the sharing of data and granting more employees access to pertinent analytics.
IT leadership certainly recognizes the benefits of shifting big data into the cloud, but getting primary stakeholders and C-suite execs to buy into the concept is more complicated. However, it does make practical business sense to leverage the pairing of cloud and big data as it will allow an optimized view of the business, and will promote decision making based on relevant data.
For example, a COO of a company that produces physical products could greatly benefit from access to data about supply chain optimization and an efficient mechanism for tracking defects. Likewise, a CMO seeking to boost customer loyalty and engagement, as well as a CFO looking for new avenues to grow revenue, reduce costs, and invest strategically also rely on data in making their decisions. Regardless of perspective, the utilization of an agile cloud-based platform and big data will drive how your company operates and achieves its goals.
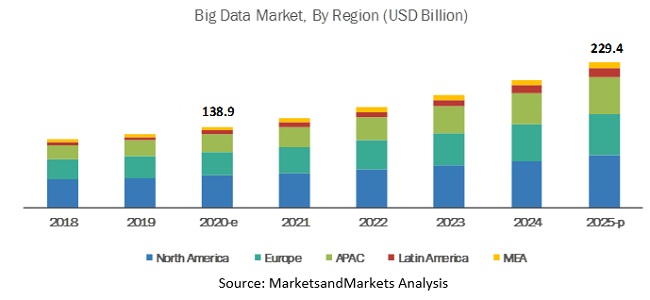
As noted in the Big Data Market Report 2020-2025, The worldwide big data market size will increase from USD 138.9 billion in 2020 to USD 229.4 billion by 2025.
History Of Big Data And Cloud Computing
Vast analytical projects are highly reliant on effective resource management as data platforms utilize large amounts of visualized hardware resources to drive down costs and optimize results. The complexity of the architecture makes such management or resources challenging. Serious consideration should therefore be given to how much data will be processed, and devising architecture conducive to the optimal performance of not only current but also future application.
Grids, computer clusters, and other high-performance supercomputers have, up until recently, been utilized as resources for high computation projects. Cluster computing is the predominant
environment for this type of framework. Virtual organizations in grid computing environments (or other distributed HPC environments) manage resources (both external and internal) dedicated to the needs of the application, though in recent years discussions of moving this execution to the cloud have been a hot-button topic of discussion. The draw to storing sensitive data locally is not surprising for security reasons, but when the volume becomes prohibitive to internal storage (such as data in enterprises), organizations find it imperative to move to cloud storage solutions.
While cloud computing might be at the heart of growing big data, cloud-based solutions for big data applications are quite different from the common variety. Conventional cloud solutions offer somewhat loosely related apps, with a fine-grained architecture aimed at serving a high user volume. These users often operate from diverse locations, independently, and often own data that is not shared or private. This data may be mainly batch-oriented and contain many interactions. It is typically relocated to cater to highly dynamic resource requirements. With that said, big data shares several common attributes with conventional scaling solutions, as well as requirements for automated management of resources.
The growth and maturity of cloud computing enterprises are refining and improving cloud environments to be more agile and efficient. Cloud providers are also expanding their services, which often include data lake architecture. This platform offers enhanced productivity suites for use in BI, cloud operations, databases, OLAP, data warehousing, and other development tools.
Frameworks for Resource Management Within Big Data Cloud Computing
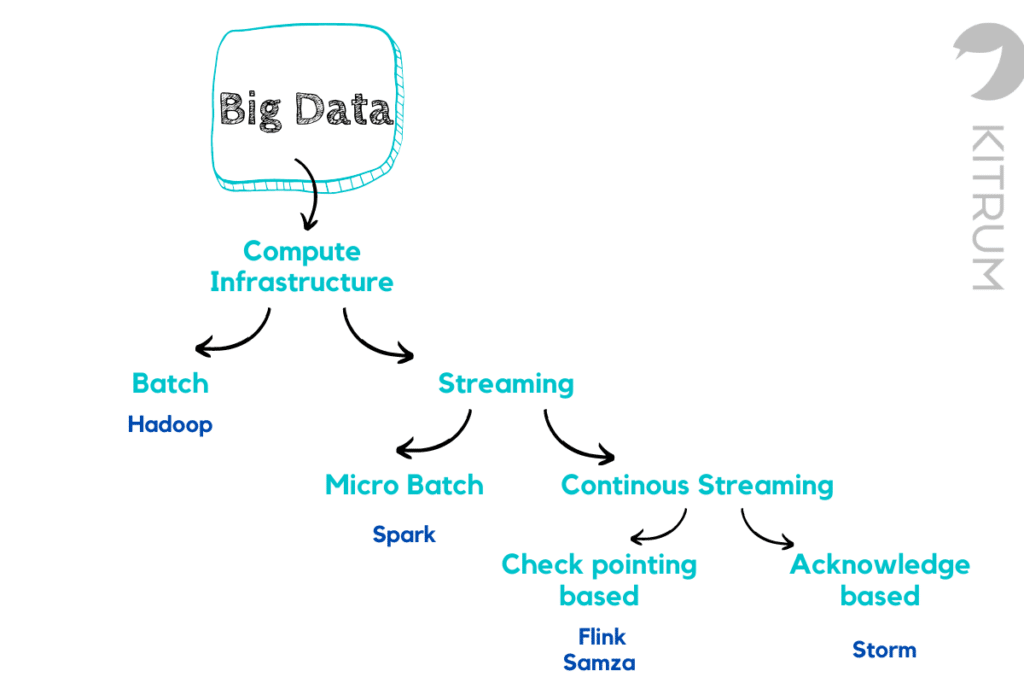
A variety of computational infrastructures have been used in different application domains to processing large databases in batch mode, utilizing commodity computational assets. Here, we aim to explore some of the prevalent big data resource management frameworks used in cloud computing environments. The below chart helps to visually map out the classification of styles of big data management constructs.
Comparing Big Data Frameworks
Contemporary enterprises, research communities, and IT industries are all feeling the influence of cloud-computing of big data, with several transformative and disruptive big data solutions and technologies emerging to promote innovation and data-driven operation decisions for many businesses. Modern data cloud computing services offer infrastructures, technologies, and big-data analytics that helps to expedite the pace of big data analysis, as well as a reduction of its cost.
While many options are available, the key lies in selecting the framework best suited for a particular business. This selection tends to boil down to the application requirements and the weighing of the upsides versus downsides of each scenario. Many of these are based on the application usage scenarios and likely involve some trade-offs. Before deploying a big data app in the cloud, several key factors need to be established. We will now discuss the pros and cons of selecting every primary management framework type.
1. Processing Speed
When evaluating the efficacy of different resource management constructs, processing speed is an important performance measurement tool that is based on the expediency of data transfer reads and writes (I/O) to memory or disk. It also measures the rate of data transfer between two communicating units of a particular period of time. It stands to reason that some resource management frameworks will perform better. However, research has found that while certain frameworks exhibited better performance for smaller tasks, others were significantly faster when dealing with more sizable data source sets. As the dataset input increases, however, all frameworks experienced a reduction in their ‘speed-up’ ratio.
2. Fault Tolerance
Measuring how the rest of the system continues to function when one component fails is referred to as fault tolerance. Hundreds of intricately interconnected nodes are evaluated when a specific task is performed in a high-performance computing system. Having one result in failure should have minimal or no effect on the computation overall. Some frameworks are much more fault-tolerant than others, with certain ones exceeding in situations where a lot of data transfer is involved. Research using the PageRank algorithm has been used to experiment with the performance of multiple frameworks, finding that performance measures well in smaller data sets, but the ‘speed-up’ degrades as data sets grow. Some datasets can get so large that certain systems are just not able to handle working with them without crashing.
3. Scalability
Enterprises rely on the timely processing of data in order to address high-value business issues. By being able to perform multiple computations on a large scale simultaneously, the effort, overall time, and complexity are reduced for business-related computations. Accommodation of large loads or changes in workload (or size) by allocating extra resources at runtime is referred to as scalability. Scalability could be used to increase the required resources (scale-up) or reduce them (scale down). Therefore, scalability involves the combination of multiple criteria into a single algorithm. Research has indicated that frameworks can generate scalable performance at varying levels as well.
4. Security
Most big data applications are moving away from in-house data storage, opting to move to a cloud environment where different users can access or record the same privacy necessitating information easily. Data integrity and security has always been paramount, but that aspect is further magnified by the widespread adoption by big data platforms of cloud computing services. By being exposed to multiple users who seek the data for their own reasons, which in turn increases the level of risk in terms of privacy and security that the data is exposed to.
The security is broken down into categories, each necessitating a different level of access for authentication and authorization via various levels of encryption. Certain frameworks utilize encryption mechanisms in their access schematic, while others allow their access and encryption to be password controlled. Still, others do not provide any system-level built-in security.
Conclusion
The rate of growth in terms of speed and data volume can be overwhelming, especially for young organizations. However, leveraging the use of cloud computing can help radically transform the efficiency and data-driven organization of any operation.
Has your organization migrated big data to the cloud? We would love to hear how this move has impacted your data analysis quality and speed. Please share with us how this has helped to improve your organizational operations.
Have a project that is related to big data?
Article by Evgenia Kuzmenko