We Stand With Ukraine
We Stand With Ukraine 
Big Data in Healthcare. How Health Tech companies took advantage of Hadoop and Apache Spark.

Big Data In Healthcare. Overview.
Big Data in Healthcare could decrease the treatment costs, forecast outbreaks of disease, help doctors to better and faster manage processes as well as getting results, and enhance the quality of medicine overall. There are different sources in the healthcare industry where already thousands of companies have used big data: clinic documents and archives, health records like lab test results, health history, allergies, etc, and IoT healthcare devices.
Big Data is a powerful tool that assists the optimal clinical decision making by healthcare providers and provides extensive analytics based on masses of retained data. One issue is the data’s aggregated nature, making it rarely readily fit into an organization’s structured framework, nor is modeled in a pre-defined manner.
However, data is unstructured to make it more adaptable to a variety of formats. More often than not, input options within a structured framework (such as checkboxes, drop-down menu selections, and radio buttons) fall short in terms of properly framing and appropriating data, making unstructured data that can be adapted to work with them retroactively. To that end, data of many different types can only really be recorded in unstructured formats. Consider how challenging it would be to group important, yet varied data regarding a patient’s preferences, clinical particulate, lifestyle and socioeconomic factors, and many other patient-specific informational components into a unified and intuitive data format to later be analyzed by various algorithms to help determine the best course of patient care.
And yet, utilization and use of rich streams of data is an unavoidable requirement in the healthcare industry, leading to an improved patient experience, level of care, management, and cost reduction of patient treatments. Currently, we are nowhere near the level of meaningful utility and harnessing the power of insight that comes from data collection. To get to that point, proper management and analysis of big data in a meaningful and systematic manner is pivotal.
How Big Data could be applied In The Healthcare Sector and what is Hadoop or Spark?
The term “Big Data” refers to a massive volume of data collected quickly for a variety of sources. It is not really meant for consumer consumption, but rather for utilization of consumer services’ optimization. As with any industry dealing with Big Data, the biggest challenge with its use in healthcare and biomedical research is leveraging such a high volume in a meaningful and productive way.
For the data to be utilized for efficient analysis, especially in a scientific community, it must be structured to be readable and stored in a readily accessible file format. Within the realm of healthcare, there are even more obstacles presented. The clinical setting calls for the use of multiple high-end hardware tools, software solutions, and often extensive protocols. Furthermore, expert users from a diversified array of backgrounds including mathematics, IT, statistics, and biology will all need to have tailored access to this data in order to be able to work together fluently in providing optimal patient care.
Sensor collected data can be stored in the cloud using pre-installed software solutions developed by experts in the analytic tool development field. AI experts will develop ML functions and data mining methods using these tools that will then meaningfully convert the aggregated information into knowledge. Once implemented, the ability to acquire, store, inspect, analyze, and visualize Big Data in healthcare will be enhanced. The key to developing such tools is to permit them the ability to annotate, integrate, and vividly and intuitively present complex data sets to assist in the data consumers’ better understanding of it.
Without being organized and formatted properly, the amassed data will simply be too diverse and disorganized to actually assist biomedical researchers. The ideal goal is to be able to effectively present the information in such a manner that users can efficiently utilize it to obtain new knowledge.
Another challenge in analyzing large volumes of data is its heterogeneity, the attribute of large scale data that renders its utility in terms of healthcare to be far less effective and informative when conventional technologies are used. High-powered computing clusters on a computing infrastructure grid are the most commonly found platforms for operating structured software frameworks.
For example, cloud computing is an example of a system that can provide a highly reliable, scalable solution, as well as a form of autonomous access, composability, and discovery of resources. These platform types serve as mediums of data receptors from ubiquitous sensors and provide the ability to analyze and interpret data, allowing users to sensibly and easily visualize it.

With IoT, processing and analysis of large volumes of data can be performed using services like fog computing and mobile edge computing that are closer to the data source. Computer clusters require the use of advanced algorithms in order to implement AI and ML big data analysis methods. This type of software and algorithms can be written in a big data suitable programming language like R or Python.
Therefore, knowledge in the IT and biology realms is pertinent to handling the assortment of data used for biomedical research, a trade combination commonly termed as bioinformaticians. The most common platforms conducive to big data work are Hadoop and Apache Spark. Let’s briefly overview these two platforms.
Hadoop
Dumping large scale volumes of data into even the most powerful computing cluster is not an efficient mode of big data utility. A far more efficient process of complex data analysis is a model that distributes the process over multiple nodes in parallel form. However, when considering the sheer size of the data, it is not an exaggeration to say that thousands of computers are necessary to effectively distribute and to complete processing the data inside of a reasonable time period. Working with that many nodes brings up the challenges of optimizing computation, error handling, and data distribution. This is where Hadoop, one of the most popular open-source applications, enters the picture.
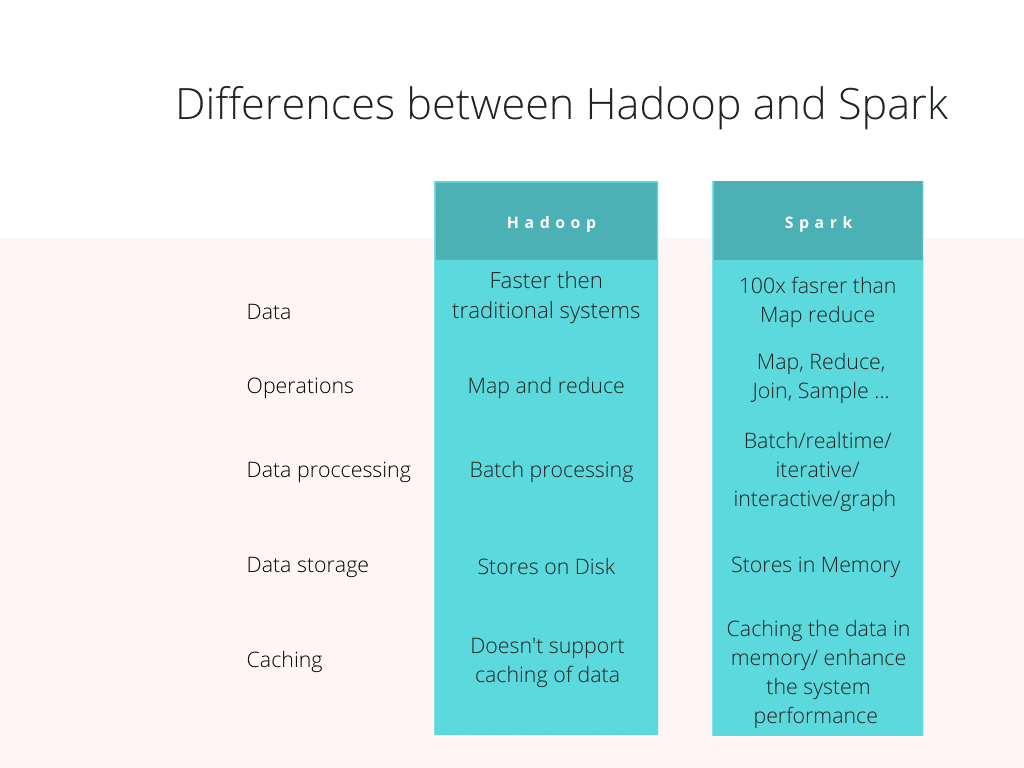
Hadoop uses the MapReduce algorithm to generate and process giant datasets while using map and reduce functions to map the logical records into pairs of intermediate keys and values while reducing those values with shared keys. This method allows for effective parallelization of computation, error-handling, and inter-machine communications across large machine clusters. The data storage is provided by the HDFS (Hadoop Distributed File System). It affords an efficient, scalable, (replica-based) storage of data, in the various cluster forms.
It is little wonder that Hadoop’s storage and processing enhancement tools have been adapted by internet giants like Facebook and Yahoo. Hadoop allowed large scale data, formerly too vast and unruly to handle, to be effectively used as data sets by researchers. In healthcare, a variety of large scale projects are implementing Hadoop to help in determining assistance in terms of using proteomic and genomic data in drug development, and the correlation between asthma admissions and air quality, as well as other healthcare aspects. When it comes to the implementation of Hadoop in the healthcare industry, the sky’s the limit.
Apache Spark
Apache Spark is an alternative to Hadoop. It is also an open-source, unified engine for data distribution including multiple high-level libraries supporting such as Spark SQL (SQL queries), MLib (machine learning), Spark Streaming (streaming of data), and Graph X (for graph processing).
Because the coding efforts required in the programming interface are minimized, these libraries are helping to more seamlessly create advanced types of complex computations. Implementation of RDDs (Resilient Distributed Datasets) can make Apache Spark a hundred times faster than Hadoop in processing through smaller datasets (via multi-pass analytics). This is a very relevant factor when the data size exceeds the memory available. Memory is more expensive than hard drive space, making MapReduce a more cost-effective method for larger datasets than Spark.
Additionally, Apache also developed the Storm tool to provide data stream processing within a real-time framework. Not only does Storm offer great horizontal scalability and fault tolerance capability built-in, supporting the analysis of big data, it also supports the majority of programming language options.
Using Big Data In Healthcare Companies (Examples For Different Healthcare Solutions)
- EHRs (Electronic Health Records)
Since every patient has a full digital record that includes medical history, allergies, test results, demographics, and many other data points, EHR is easily the broadest spread of big data utilized in medicine. Secure information systems allow providers from private and public sectors to access shared records of patient information. Each record consists of a large, modifiable file, meaning that doctors don’t need to be concerned with data redundancy or the hassle of paperwork.
Due to the massive presence of data, EHRs can track prescriptions to determine if the doctor’s orders are being observed by the patient. Likewise, EHRs can provide notifications and warnings, as well as reminders about the need for additional lab tests.
According to HITECH research, as advantageous as EHR is, and while its implementation in the US has grown by 94%, many countries, including those in the EU are lagging behind and struggling to adapt to it. Luckily, a directive from the European Commission (a rather ambitious one) has been drafted to help rectify matters in that regard.
In the United States, Kaiser Permanente has taken the lead, hoping to provide a model that can also be followed by countries in the EU. Their implementation of HealthConnect, a data-sharing medium, makes accessing EHR data far easier across all facilities. A report from McKinsey regarding big healthcare determined that the integrated system has already generated about $1 billion in savings by reducing the necessity for lab tests and office visits, and has gone a long way in improving cardiovascular disease.
- mHealth (Mobile Health And Mobile Computing)
The utilization of digital pedometers built into smart devices (portable or wearable) is a common trend in today’s world. Because smart portable technology is rapidly expanding, healthcare needs to update its infrastructure in order to accommodate the use of such devices. The utilization of mobile devices in terms of public and medicinal health has become known as ‘mobile-health’ (mHealth).
Adoption of this type of technology is especially prevalent in monitoring and treating individuals with chronic diseases like cancer or diabetes. Mobile technology is ever-more frequently leveraged by healthcare organizations with constantly developing innovative and novel ways to provide patient care and promote patient wellness.
The efficacy of mobile device utilization is especially evident in the improvement seen in terms of how a patient and a provider communicate. Google and Apple have both developed dedicated platforms (Google Fit and Research Kit, respectively) intending to research and improve methods of tracking health-based stats. These innovative devices use embedded sensors to seamlessly interact and to collect data for the purposes of integration, informing both the patient and their physician about the real-time status of the patient’s health. Using such devices helps promote patients’ healthier lifestyle choices by improving their ability to plan and chart the course of their own wellness, essentially setting them up to advocate for their own overall health.
- Could ‘Big Data’ Help Find A Cure For Cancer?
Before leaving office from his second term as chief of state, President Obama put in motion a program known as Healthcare Moonshot. Its novel intent was to use healthcare collected data to accomplish a decade’s worth of research dealing with curing cancer but in half of the time.
By tracking recovery rates and treatments associated with recovery, big data can be utilized by researchers in the medical arena to correlate data and identify trends that have the highest levels of efficacy. For instance, an examination of samples taken from cancer tumors linked up to patient records can help researchers identify particular mutations, track how certain treatments affect particular proteins in cancer cells, and work to find those trends that are most effective in order to secure the best outcomes for patients. Sometimes, this research can lead to unanticipated finds. One example of this is the linking of an antidepressant (Desipramine) to its ability in curing particular forms of lung cancer.
While it is great to compile a lot of data, the real key is the establishment of interoperability where patient databases from a variety of medical institutions (hospitals, nonprofit organizations, academic research, etc.) are linked together so that the collected data can be evaluated cumulatively. In terms of cancer research, this linking up permits access to patient biopsy records for a more far-reaching scope of available data.
A particularly notable use case of healthcare’s big data adoption is a genetic sequencing of samples of cancer tissues that come from patients in clinical trials. This data would then be appended to an ever-growing cancer database.
- Enhancing Security And Fraud Reduction
Most healthcare organizations have been victims of some form of breached data, roughly 93% of them, according to studies. The number is so high for a simple reason: personal data is overwhelmingly valuable and has a high asking price on the black market. Of course, such breaches can have drastic consequences.
For this reason, healthcare organizations, in particular, have begun to strengthen their security measures, specifically by leveraging analytics. This is done by tracking any online behaviors that might be indicative of a cyber attack, like network traffic changes, for example.
While many logically believe that by its very nature, big data actually make healthcare organizations much better targets for cybersecurity concerns, technological advances in terms of virus detection software, encryption, and firewall tech, will supplement the additionally needed security, the benefits of which will far outweigh the risks.
Analytics can also greatly reduce fraudulent claims by streamlining insurance information. This promotes a better patient experience and providers are able to be compensated faster for their work. This is firmly evidenced by $210.7 million in savings reported by the Centers for Medicare and Medicaid Services in terms of mitigating fraud.
- Managing Personnel And Smart Staffing
A common struggle in most healthcare institutions is the ineffective distribution of staff and personnel. Organizations constantly run into problems dealing with the lack of a fluid system, causing certain departments to be overcrowded, while others end up severely undermanned. This causes lower motivation for work on one end, while high anxiety environments on the other.
When the healthcare-based workforce cannot operate in an engaged and cohesive manner, the quality of patient care is reduced, service rates suffer setbacks and the error propensity increases. However, using big data tools in a healthcare environment allows for the streamlining of key areas, promoting better staff management. Using HR analytics can help healthcare organizations to optimize their staffing needs, better allocate staffing resources in a time-crunched environment, and forecast demands for operating rooms. Overall, this helps to streamline patient healthcare.
Streamlining HR and staffing operations on data-based analytics helps to overcome the staff distribution issue, often with the use of an effective HR board. Analytics help in better predicting when certain departments experience their busiest times, allowing management to more accordingly distribute personnel among departments and areas of the organization in a far more optimal manner.
- Methods Of Managing Advances Risk And Disease
Another noteworthy upside of using big data in healthcare is in terms of reducing the risk of hospitalization of individuals with chronic conditions. By analyzing data related to symptoms, medication consumption, and patient visit frequency, a healthcare organization can not only better streamline its own finances and economics, but it can better tailor a plan of preventative care measures, thereby reducing the frequency of patients’ hospitalizations, driving down costs of patient care, as well as ensuring that resources and space are allocated to be available to those patients who need the most attention and help. In this way, the utilization of analytics will clearly vastly improve an organization’s ability to save and better the lives of their patients, as well as save money in many pertinent operation areas.
Shortcomings Of Big Data In Healthcare
With the multifaceted benefits of using big data in healthcare come some notable downsides. When a lot of data is analyzed it can all too often overstate factors, leading to incorrect asset and staffing allocations.
A vivid example of this was the use of the Google Flu Trends project. The idea was to help the CDC (Center for Disease Control) better predict influenza-related visits using traditional statistical modeling. However, the effect of Google Flu’s data compilation led to an overstating such visit prediction by nearly double in 2013. The initiative shut down in 2015 due to its ineffective returns.
In what was ultimately a flawed approach, it was theorized the predictive nature of Google Flu actually led to more people finding out about it via news and media outlets, which in turn triggered more influence based querying in searches. The increase in user searches, in turn, led Google Flu to predict a far higher number of influenza based visits than were actually warranted. In this way, Google placed far too much reliance on big data, rather than establishing a more traditionally modeled method of data collection and use of analytics.
While it is hard to deny the benefits and positives of big data in terms of healthcare, Google Flu is one of the examples that expose the shortcomings of relying on big data in this manner. A broader overview seems to indicate that in some ways healthcare might not be ready to be more fully integrated with big data analysis at this time.
Some of the reasons lie in the fact that current healthcare is just not accustomed to using so much data. Another aspect of it lies in the physicians not being interested enough in this realm to actually make use of it. More importantly, it does carry a sting of introducing unforeseen threats to patient safety, privacy issues, questionable data quality, and other yet undermined big data shortcomings.
Want to implement Big Data into your Healthcare project?
Article by Evgenia Kuzmenko