We Stand With Ukraine
We Stand With Ukraine 
Data Lake Implementation To Boost Business Intelligence
December 7th, 2020
With Big Data’s emergence, radically new methods for data management are needed because the traditional BI methods for Enterprise Data Warehouse building and data marts are no longer able to efficiently keep up with current data-related demands. These needs spawned the new concept of BDL (Business Data Lake), a principle of the data repository that will, for a low cost accommodate the storage and handling of massive amounts of the raw form of structured, unstructured, and semi-structured data. This approach allows for the presentation of a global enterprise view of business while permitting the ability to perform ‘line of business’ analysis specific to the particular business. Data Lake storage permits data to be stored in its raw, ‘as-is’ form, without necessitating any restructuring, dashboard and visualization adjustments to accommodate big data processing, analytics, or machine learning, with only metadata information being maintained for historical traceability and evaluation for future refinements.
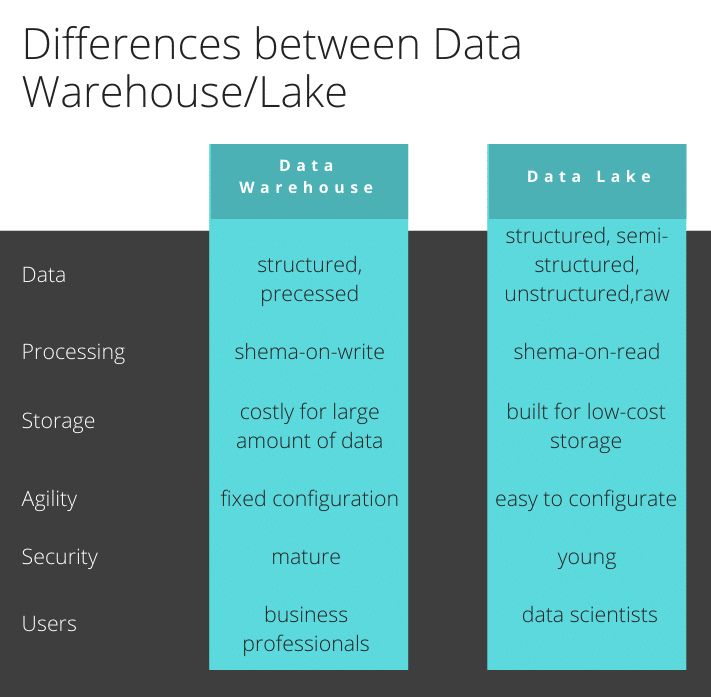
Differences Between Data Warehouse And Data Lake Processing
In an effort for greater information attainment and insight derivation, the concept of data warehousing came out as a data compilation solution in the 1980s. Gathering data out of all source systems of the company, a data warehouse was to be a target database for all of its related data. This example was that of a comparative database since data from various desks can be merget together to enable its presentation in a physical data model. Essentially, the database schematic is centered around relationships between various tables, with most relational databases like MySQL and PostgreSQL.
The way that data sources associate into the data warehouse is through an ETL (Extract, Transform, and Load) method. The approach follows a schema-on-write template. In other words, one when the design addresses the issues. Basically, a data warehouse gathers the data sourcing from major applications with a schematic and structure that is predetermined. When transfering data from one database to another, some information needs to be determined ahead of time to adequately format and adjust the format and structure of the data as it resides on one database to the structure and format of the one it is being moved to.
There are some options when it comes to how data warehouse engineering teams build the data warehouse. A three-layer architecture schematic is one of the most popular warehouse architecture. In this three-layer form, the first layer is the staging, the second is the warehouse, and a dimensional model is then used to build the third (data mart) layer.
Around 10 years ago we saw the new concept of a data lake. In simple terms, a data lake is a concept of pooling all data, structured or unstructured in the same storage location. A sample of this kind of data lake architecture is a data infrastructure of Apache Hadoop that allows the storage and processing of huge volumes of data, regardless of its class or sort.
A data-lake architecture follows a schema-on-read method. Basically, you don’t necessarily have to set up the data structure and shema to store raw data. When data is transferred to a data lake, it is simply brought over in its existing form and stored without any gatekeeper qualifiers to its structure or arrangement. It is when the data needs to be read, code is designed to read that data appropriately without needing it to be in a particular form when being read. Whereas data warehousing utilizes the Extract, Transform, and Load approach, data lakes use the Extract, Load, and Transform approach.
Data laking is usually leveraged for exploratory goals and cost-efficiency. It allows companies to collect insight from both the regulated, refined data and also raw-form data that had previously been unavailable for analysis. Exploration of raw data is likely to result in some business questions. On the downside, without the governance of data, data lakes can pretty fast grow into something more resembling a data flood.
Data Warehouse vs. Data Lake (An Actual Study)
A study designed with the intent of improving the comprehension of using data lakes enterprises conducted by Marilex Rea Llave, consisted of interviews with 12 experts who had experience in the implementation of data lakes across various enterprises, to find out the areas they identified as a most important argument for doing so. The study closed with such purposes for this approach.
- The up-front effort required was reduced since the absorption of data did not require any formatting changes upon the initial schema.
- Easy acquisition of data.
You can find a full report here.
Data Lake Benefits
There are multiple benefits of data lakes:
- Affordable BI environment: This enables us to recognize and specify extra BI queries.
- Concentrate on catering to only the business needs: Companies are always changing, strategies are always improving and what was significant when you just started the development of a data warehouse, may not, at this point be up to date.
- Provides a process and range of upgrading the verification of requirements as they evolve: Plans can be adapted as per the changes in the business standards. These requirements can be verified and revised as many times as the business demands it.
- Frequent, speedy testing: As business terms progress, the precision of data analysis will stay current and relevant.
- Exponentially shortened design-analysis cycles: Data warehouse setups call for 6 to 12 months, whereas a data lake design is a matter of 1 to 2 weeks.
- Dramatic cost-cutting: It’s much cheaper to organize and maintain when considering ETL programs, integration, and data modeling requirements being very minimal for data lakes.
What Makes Data Lake Efficient
Hadoop
Data Lake architecture is possible with an open-source framework named Hadoop, which is the primary data repository mechanism. The Jonah Group published a whitepaper on Data Lakes in which they explain that one of its main benefits is its cost-effective storage in Hadoop via utilization of writing modes that do not rely on a schema and read modes based on one. When data is being written to the Hadoop file system, it will not require a schema defined, negating the need for a centralized Data Warehouse in order to be stored. The data will all be available in a staging environment for retrieval, review, analysis, and reporting. Essentially, Data Laking affords the functionality of a traditional Data Warehouse’s centralized nature, without necessitating upfront costs for development.
Therefore Data Lakes provide an approach that is both cost-efficient and agile, allowing for the development of models specific modeling for the construction of dimensional models for a targeted subject area, also known as Data Marts.
Eliminates Upfront ETL Processes
The building of a data warehouse accounts for a large portion of BI costs, the ETL development process requiring a serious financial undertaking, which includes costs of initial license acquisitions, as well as costs for development and maintenance. Companies can alternatively get around the massive financial investment by using Pig language to develop ETL scripts with Map Reduce. Leveraging Pig language also permits developers to need to be less focused on ETL programming, in order to pay greater attention to analysis.
Expanding Predictive Focus Over Simply Reporting And Analysis
BI requirements have evolved in that business owners are not only interested in those things they know or those aspects they know that they don’t know. They want to also understand the unknown unknowns, which means that there is a greater demand for prediction over strict analysis and reporting. Being able to accurately forecast the future is the difference between the mindset of good leaders and those who are more reactive. The architecture of Data Laking enhances the ability of businesses to better read the future by more finely dissecting and examining data.

Can Data Lake Replace Data Warehousing For BI?
While Data Lakes certainly offer multiple benefits over Data Warehouses, both in terms of massive data collection and cost-efficiency, the data cannot be fully trusted without verifying the data’s integrity. Pooling raw data together from multiple sources, cleaning it up, and assuring its quality to be used for business modeling accounts for 80% of the time and work, a fact often overlooked by data scientists.
In that sense, it is hard to ignore the benefits of properly organized, quality data inherent to both the architecture and discipline of a Data Warehouse. Businesses still need a core set of KPIs to define business health. Reporting, especially of a regulatory nature, still calls for high governance of information.
Companies need to be clear about what they are seeking to achieve with data and technology in their business strategy. A company that does not intend to involve itself in data science, for instance, will likely get minimal benefits from a data science & analytics platform mainly focused on growing machine learning and AI tech. Companies that sort and govern their data in a glossary-like structure are unlikely to derive much value from dumping all of the existing data into a Data Lake.
Want to implement Data Lakes effectively for your business? Drop us a line here.
Article by Evgenia Kuzmenko