Working with Big Data requires obtaining special instruments to deal with voluminous piles of information. The data can be structured, unstructured, and semistructured, making it difficult to choose the right tool to store, analyze and utilize. Elasticsearch is probably the most popular search engine with a strong community, support, and a lot of instructions.
Today users generate a lot of data via social media, providing information for various websites or messengers. The most important of what you get from it is not the data itself but how you can use it. To make it valuable, you should be able to analyze it. Only in this way can you get insights, find patterns and understand how to apply them to maintain your business and reach your goals. You can also improve your services, enlarging the number of customers or spot the faults in the performance of your product and minimize fraud.
For example, you can increase the quality of your services by providing your users with the best search results. Such additional factors as user age, brand preferences, location, and previous searches will allow you to provide a better user experience.
Reasons to use Elasticsearch for unstructured data
Relational databases are perfect for storing structured data. For example, you can manage user numbers, locations, or emails with the help of SQL. But how about user information, such as previous orders or wishlists? It is unstructured information. And only combining search requests, history of purchases, and price range and analyzing such data can help you come up with the best results.
Elasticsearch is an open-source full-text search and analytics engine. With its help, you can store, search and analyze information almost in real-time. It’s a distributed NoSQL database that allows you to use documents to manage non-structured data rather than schemas or tables.
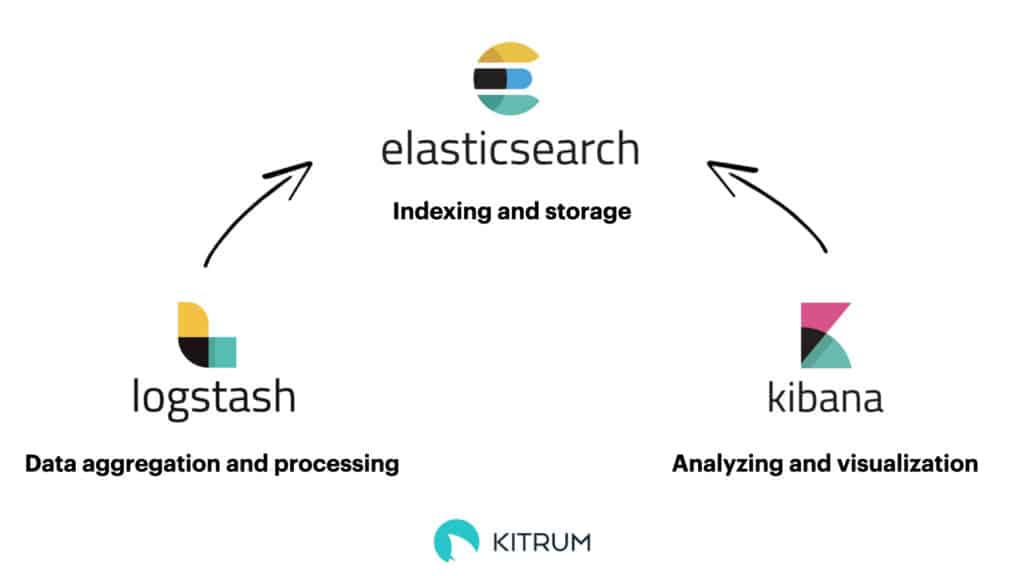
Elasticsearch empowers you with other tools to work with the data, such as Logstash and Kibana. Those three instruments create an ELK stack. Logstash collects data from different sources, converts it, and sends it to Elasticsearch. Kibana is a visual tool that shows data saved in Elasticsearch to enable further analysis for better business decisions. ELK also monitors infrastructure, makes troubleshooting more effective, and provides security analytics.
For a better understanding of how you can benefit from Elasticsearch, Kibana, and Logstash we will focus on the functionality of each of them.
How does Elasticsearch work?
Elasticsearch performs a web search, log analysis, and Big Data analytics. It is a scalable full-text open-source search and analytics engine. With its help, you can store, analyze and search significant volumes of data. ElasticSearch is common to use for applications with complicated search functionality and needs.
Here at KITRUM, we have a client for whom we build an e-commerce platform with a wide variety of partner vendors and thousands of clothing items they sell. The variety of items and the multiple possibilities of search requests could lead to irrelevant return results and a long time for the website to respond. It might result in a poor experience for the customers and their potential loss.
The poor search performance results from the database’s performance at the backend. If we chose to use a relational database, all data would be stored and distributed in numerous tables and finding the information requested by a user would take time. Complex queries, in combination with huge amounts of data, always lower the performance of relational databases.
The necessity to deal with voluminous data and perform a search in real-time demands implementing NoSQL databases, such as Elasticsearch. It’s better for storage and retrieval, as it doesn’t have relations, constraints, and transactional behavior. As it is scalable, you can create various nodes without additional software. So we implemented Elasticsearch while developing an e-commerce application for our client. It also allowed our client to reach data and analytics fast and easily.
The data in Elasticsearch is stored in JSON document format, which can be later queried for retrieval. A set of keys corresponds to their values, which can be numbers, dates, geolocation or any other data type. The data structure in Elasticsearch is named inverted index. It speeds up the performance of a full-text search. It creates a list of unique words that documents contain and defines the documents that include each word.
While indexing, the documents are stored, and inverted indexes are created, allowing search in real-time. You can add or change JSON documents in a specific index through the API index.
Elasticsearch features are performed through REST API, through which you can document the index, retrieve documents, submit queries and output results, override default options, and build your own mapping.
The key benefits of using Elasticsearch
Many big corporations, such as Netflix, Uber, Shopify, Tinder, and GitHub, use Elasticsearch as a search engine. These are the key benefits that it brings:
- Fast and easy access: Documents are kept near the appropriate metadata in the index. Consequently, the number of data reads is reduced, and the search result response is increased.
- Deals with a huge amount of data: Elasticsearch gets the needed query data within microseconds, compared to typical SQL database management systems, which shows the results in about 10 seconds
- The search engine is scalable: The distributed architecture of Elasticsearch enables it to scale up to thousands of servers and accommodate petabytes of data. Customers no longer need to manage the complexity of distributed design because it has been handled automatically.