Artificial intelligence (AI) and machine learning (ML) have a significant function in cybersecurity, through protection tools that analyze data from thousands of cyber accidents. Machine learning (ML) is a heart of AI — a sort of system that allows computers to explore data, discover previous experiences to make decisions, almost like humans do. Machine learning algorithms in cybersecurity can find, identify, and analyze security issues. A lot of current protection tools, like risk intelligence, already use ML.
Here at KitRUM, we’ve built dozens of teams to implement ML for endpoint protection, application security, detecting malicious queries in web attacks, detect anomalies in HTTP requests, etc. So we’re pretty familiar with the process.
Most of the ML algorithms carry out the next functions:
Regression
Regression (or forecasts) is pretty straightforward. By knowing and understanding the current information we can predict changes in future data. For instance, think of gasoline price prediction depending on world situations and economic development. If we’re talking about cybersecurity cases, we can use regression in fraud detection. The hallmarks (number of shady operations, location, devices, etc.) identify the probability of fraudulent acts.
Here are samples of ML methods used for regression tasks:
- Linear regression
Machine learning is mostly in charge of limiting the error of a pattern or creating the most precise forecasts possible, at the expense of explainability. ML borrows and reuses methods from various separate areas just like a statistic. It applies to forecast values under a constant scope, (e.g. sales, logistics) rather than attempting to sort them by classes (e.g. books, magazines). There are two common forms: Simple regression and multivariable regression. - Polynomial regression
This regression type is primarily used to determine or explain non-linear situations such as the spread of the virus, developers’ salary based on years of experience, etc. ML experts usually use Python to build this type of regressions. - Ridge regression
It is a method to analyze several regression data that come down with multicollinearity. In cases with multicollinearity, estimates are different so they could be far from the real numbers. By adding a degree of inclination to the regression evaluations, ridge regression cuts back the standard errors. - Decision trees
Decision Tree models using 2 actions: Induction and Cutting. Induction is when we create the tree i.e set all of the graded resolutions limits according to our data. Pruning is the method to take off the needless forms from a decision tree, minimize the sophistication to make it simpler to read. - SVR (Support Vector Regression)
SVR allows being flexible to determine how much error is adequate in our example and uncover a suitable line to match the data. - Random forest
A great amount of comparatively unrelated examples (trees) working as a group will exceed any of the separate parts of models.
Classification
Classification is as simple as anything can be! For instance, you have two categories of pictures that are classified by type, in this case, computers and phones. For cybersecurity purposes, a spam filter that distinguishes spam from specific messages may serve as an illustration. Spam filters were potentially the first ML method used in cybersecurity activities.
These types of learning methods were typically only used when the nature of classification was already known to the computer/person. These methods are known as supervised learning. So, for this method to work, all the classes of the category should be defined beforehand. Below, you will find the list of processes that are related to algorithms:
Machine Learning for Classification
- Support Vector Machine (SVM)
- NaiveBayes
- Random Forest Classification
- Kernel SVM
- Decision Tree Classification
- Logistic Regression (LR)
- K-Nearest Neighbors (K-NN)
Even though most people tend to find that SVM and Random Forest Classification delivers the best outcome, machine learning doesn’t have a “one size fits all” rule to it. Checking out all these methods is highly recommended as SVM, and Random Forest Clarification may not work with the task you probably have in mind!
Clustering
The only significant distinction between clustering and clarification is that the information that has been put into the system does not have any classification. This is also known as unsupervised learning. Clustering is mainly used for tasks like forensic analysis, because the elements of the consequences and the method is unknown, which is what clustering is used for. Forensic analysis requires that anomalies must be found, which is done by the machine classifying all the activities done in the incident. Malware analysis, such as spyware or secure email gateways, all use clustering as a means to find anomalies to separate the legal files from the outliers.
Behavior analytics is another intriguing area where clustering may be used. For example, the system can cluster the application users so that they can be narrowed down to be in a particular group, if possible.
Clustering isn’t typically used to solve problems but rather to prevent one. They are more like a subtask executer, much like the maintenance of pipelines to decrease risk! They can be used to group users separately, which can reduce the risk value in the foreseeable future.
Machine Learning For Clustering
- DBSCn
- K-means
- Mean-shift
- Bayesian
- Agglomerative
- K-Nearest Neighbors (KNN)
- GaussianMixtureModel
- Mixture Model (LDA)
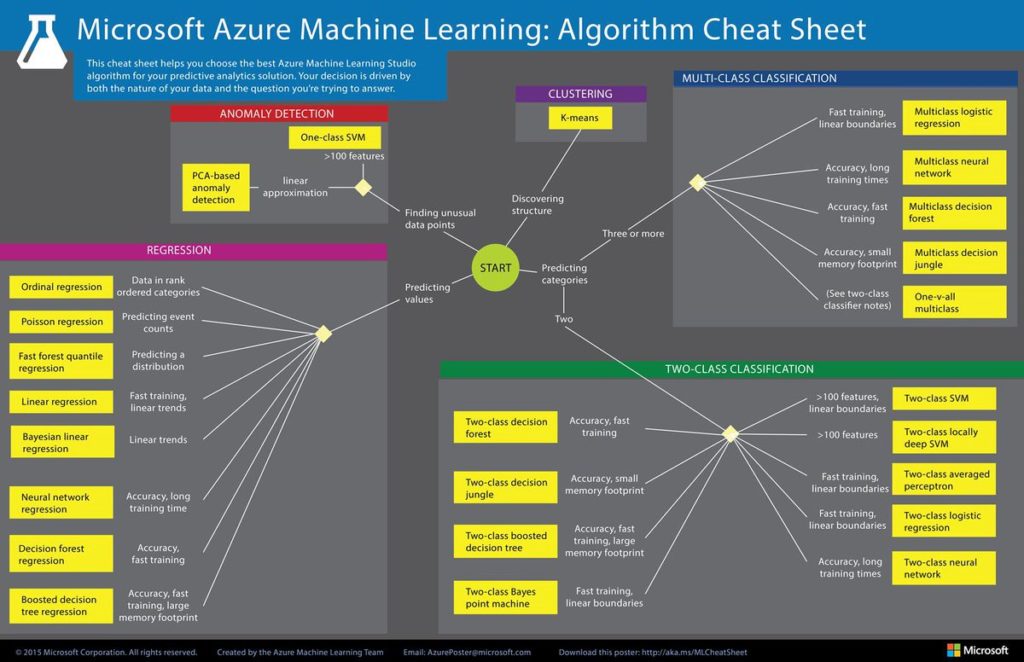
I love this pic, it shows how does all these works, in nutshell. I grab this scheme from Microsoft, and you can take it also to explain ML for your managers or marketers:)
Real-Life Examples of Using ML for Cybersecurity
Spam Filler Applications
Each mail service provider uses spam filter algorithms that are built with machine learning approaches. Spam detection mainly uses the Naïve Bayes algorithm, which is a very common machine learning approach and is based on a statistical approach. Training, as well as Testing, are the two phases of machine learning. Owing to the complexity of supervised learning, the Naive Bayes algorithm utilizes a dataset that identifies the samples. Essentially, the Naive Bayes algorithm uses word frequency throughout the email message, and thus, the training dataset includes words, number of terms, and class details for each sample.
Network Intrusion Detection and Prevention
Understanding the network environment and generating security policies may be the two important aspects to focus on when it comes to traditional network security methods. Still, there are a few other aspects to consider that contribute significantly:
Policies: Legitimate and dangerous/malicious network connections may be distinguished using security policies. Besides, security policies implement a zero-trust concept. However, it is quite challenging to create as well as maintain said plans over a large number of networks!
Environment: Many companies do not provide specific naming protocols for programs and workloads. As a consequence, protection departments tend to invest a lot of time deciding which collection of workloads is part of the application.
Fraud Detection
To understand how machine learning can be used for fraud detection, I’ve built little scheme:
Below are some of the Machine Learning concepts and algorithms which are used for fraud detection:
Supervised Learning
Supervised learning is perfect for cases like fraud detection in FinTech. All the input, in a supervised learning model, has to be labeled and classified as Good and Bad. This is because this model cannot detect fraud that was not classified in the historical data, from which the model had learned since supervised learning depends on predictive data analysis!
Unsupervised Learning
This type of model updates itself using the new information that it continuously processes and analyzes from and updates according to the findings.
Semi-Supervised Learning
This operates in situations where identifying information is either impractical or too costly and needs the research of human experts. A semi-supervised learning algorithm stores information on essential group variables even though the group identity of undefined data is uncertain.
Reinforcement Learning
A reinforcement learning algorithm helps machines to identify optimal actions within a specified setting automatically.
Botnet Detection
In a network-based botnet identification technique, malicious traffic is detected by analyzing network traffic across a range of criteria, like network traffic activity, traffic trends, reaction time, network load, and link behaviors. Network-based solutions are also split into two categories: active monitoring and inactive monitoring.
Conclusion
The effect of AI on our lives will continue to develop as more technology is incorporated into our daily lives. Many analysts suggest that AI is having a detrimental impact on technology, while others say that AI will significantly change our lives. For information protection, the significant advantages depend on quicker risk identification and reduction. Doubts concentrate on the capability of hackers to implement increasingly sophisticated security and technology-based assaults.
















