We Stand With Ukraine
We Stand With Ukraine 
Why It’s Time to Move On From Hadoop

Once a giant in the realm of Big Data, a Java-based software framework Hadoop, played a pivotal role in ushering enterprises into the era of massive data processing. However, its prominence has weakened over time and now stands at a crossroads.
When Hadoop went open source back in 2007, it paved the way for businesses to leverage massive amounts of information and scale without worrying much about the expense. Of course, being new at the time, it faced some initial challenges in security and the speed of executing queries. Fortunately, most of these issues were patched later on.
As the level of data rapidly increases, businesses require immersive experiences that directly embed data into the workflow. Streams from multiple sources, in addition to the demand for real-time insights, are testing the traditional dashboards and making them fall short.
Data from Google Trends has revealed that the Hadoop framework reached peak popularity from 2014 to 2017. Since then, there has been a clear decline in searches for the product.
More internal data products are relying on emerging technologies like Machine Learning and AI in a form factor that resonates with everyone.Thus, many people are eager to understand: is Hadoop outdated, or is Hadoop still relevant in 2024? Let’s together explore what happened to Hadoop and why it’s time for your business to move on from Hadoop.
What is Hadoop?
Imagine you have a gigantic library filled with books, and you want to analyze information from all these books simultaneously. However, going through each book one by one would take an enormous amount of time. Here is where Hadoop can help you.
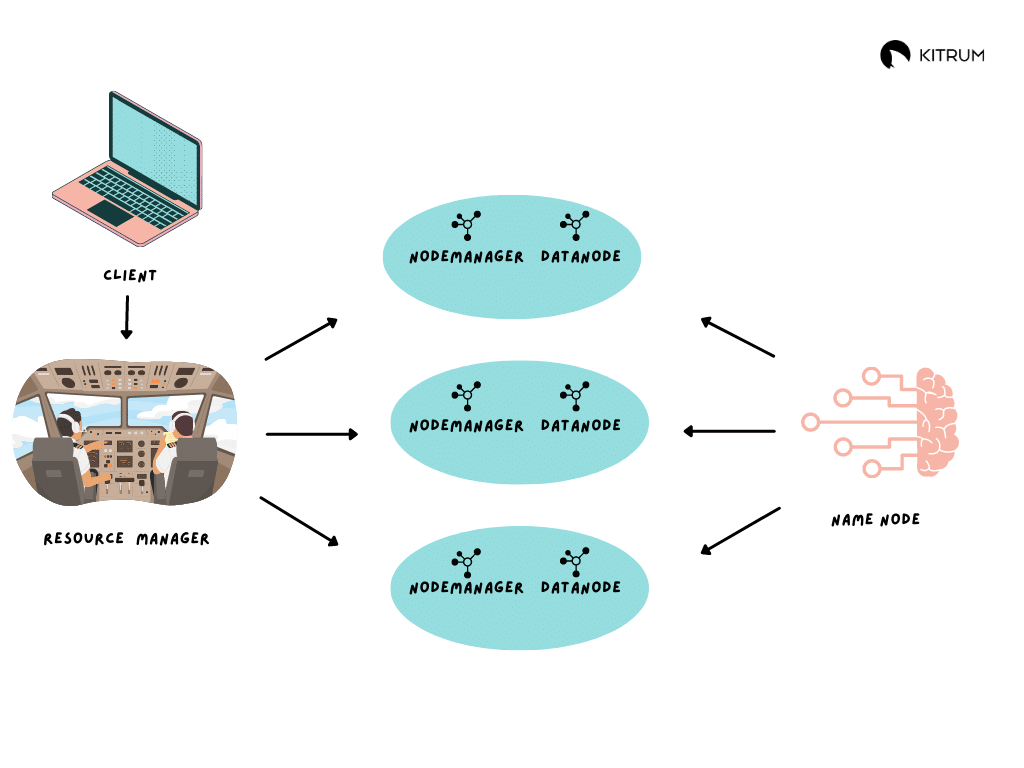
Hadoop is like having a team of people to read different books simultaneously. Each person (or “node” in Hadoop terms) is responsible for concurrently processing a portion of the books. Once everyone is done, they share their findings, and you get a comprehensive analysis of all the books much faster than if a single person tried to read them sequentially.
Hadoop is a distributed processing framework that allows you to analyze large data sets efficiently by dividing the workload among multiple computers, making complex data tasks more manageable and faster to complete.
Using commodity servers that run various clusters, Hadoop promises a low-cost, high-end approach to establishing an architecture for big data management to support advanced initiatives for analytics.
Over time, Hadoop spread to multiple industries to use analytics and reporting applications that combine traditional structured data as well as semi-structured and completely unstructured data. It includes web clickstreams, information regarding online ads, social media data, medical records, and manufacturing equipment sensor data.
When using a standard commercial copy of Hadoop, it will include most of the following as part of the distribution:
- Alternative execution and data processing managers that run alongside or on top of YARN to handle clusters, caching, and other performance enhancers.
- Apache HBase is a database management system that uses columns modeled after the Google Bigtable project running on top of HDFS.
- SQL-on-Hadoop tools, including Spark SQL, Hive, Impala, and Presto, provide various degrees of SQL standard compliance to query data stored in HDFS.
- Development tools for MapReduce, like Pig.
- Management and configuration tools like Ambari and ZooKeeper are helpful for administration and monitoring.
- Environments for analytics like Mahout supply analytical models for data mining, predictive analytics, and machine learning.
Why replace Hadoop?
So, you may wonder: What is the problem with Hadoop? Well, there are several of them. Let’s explore some major aspects that highlight the reasons for transitioning away from Hadoop.
1. Cloud computing
A significant contributor to Hadoop’s downfall was cloud technology expansion. The vendor market in this niche quickly became crowded. Most of them provided big proprietary data processing services that offered features identical or superior to that of Hadoop. Furthermore, they provided the functionality hassle-free manner that was far more efficient. Unlike Hadoop, customers no longer needed to worry about maintenance, administration, or security.
Cloud computing services offer pay-as-you-go scalability depending on how much storage is used over time. Too many businesses were stuck with 10TB clusters running Hadoop without needing that much data storage.
2. Containers and new data visualizations
In terms of processing speed, Hadoop has become obsolete over time thanks to the creation of new configurations like Spark. This tool is not bound to the standard distributed file system, which allows it to leverage alternative storage systems and run in containers with Kubernetes. Moreover, Spark offers the ability to view data using graphs.
3. Decline of open source ecosystems
The Apache Software Foundation announced in April 2021 that 13 projects related to big data as part of the ecosystem were retiring. It also encompassed Hadoop software. Ambari, a recent technology designed around managing Hadoop clusters, is considered outdated today.
4. Scaling
Hadoop poses challenges due to its monolithic nature, trapping organizations with the initial version even as data volumes grow. Upgrading requires replacing the entire setup, incurring significant costs. Alternatively, running a new Hadoop version on older machines demands increased computing power and self-maintenance, making it time-consuming and costly for users handling cluster components.
5. Lack of support
Hadoop still needs to support the transition into other innovations, such as machine learning. You can only use AI with Hadoop if you tie the platform to a third-party library.
Since Hadoop relies on batch processing, the response time for analytics is low. You must use platforms outside of Hadoop to view data in real-time.
Although you can utilize Hadoop alongside your existing infrastructure, it can no longer serve as the foundation. All historical data is stored in Hadoop HDFS, which can process and transform into a structured, manageable form. Upon completing the processing with Hadoop, the output will need to be sent to relational databases for reporting, BI, and decision support.
The framework for Hadoop does not work well with small datasets; instead, other tools available in the market can accomplish this much faster. In addition, Hadoop is more expensive when working with small data than other tools. Hadoop is only possible for production use with significant understanding. Many companies dealing with sensitive data can move slower than they want using Hadoop. Still, it can encrypt data and is compatible with volumes from numerous sources.
Even though new tools like Spark, Hive, and Pig were meant to work as an overlay to Hadoop to overcome the platform’s shortcomings, it failed to compete with modern solutions.
NoSQL databases like MongoDB and Hazelcast mean that the issues that Hadoop was designed around solving and supporting are now being fixed by single solutions rather than the black-and-white approach that Hadoop was built with. It needed to be more flexible to evolve past its batch-processing software.
A lack of support for on-the-fly querying, dynamic schemas, and new cloud technologies have loosened Hadoop’s grip.
Eventually, businesses dealing with Hadoop infrastructure, like Hortonworks and Cloudera, saw less adoption. It resulted in both companies merging back in 2019, with the same message ringing out from various corners of the planet in unison that the framework is simply dead.
6. Hadoop’s Real-Time Constraints
Building upon the challenges highlighted above, another significant drawback of Hadoop pertains to its real-time constraints, impacting both operational support and data processing – its inability to offer real-time responses. Users seeking assistance or quick data analysis in Hadoop may experience delays, impacting efficiency, especially in fast-paced environments requiring swift decision-making without prior notice.
What is better than Hadoop?
Here, we can shift gears to discuss Cloud Computing. As a modern alternative to Hadoop, Cloud Computing offers several advantages that differentiate it from the traditional Hadoop framework.
- Unlike Hadoop’s monolithic technology, Cloud Data platforms provide flexibility in solution size, allowing easy adjustments based on business needs.
- The pay-as-you-go model in cloud solutions ensures cost flexibility, contrasting with Hadoop’s fixed cluster size. Although cloud storage costs may currently be higher, the cloud’s decreasing costs over time and the increasing expenses associated with Hadoop make cloud solutions more cost-effective.
- Cloud’s modern features, real-time reactivity, and seamless integration of resources outshine Hadoop. Cloud platforms offer more possibilities, such as remote data access, real-time processing, and integration with existing resources, making them more versatile.
Hadoop, a legacy technology, lacks real-time capabilities and processes data in batches. The modernity of the cloud introduces bugs and complexity, but it simplifies maintenance, as users pay a subscription fee without worrying about upgrades or scaling. Unlike Hadoop, cloud providers offer professional support, making cloud data platforms a simpler and more user-friendly solution.
Is Hadoop still in demand?
Hadoop remains applicable in specific cases, especially for big data processing and analytics tasks. Nevertheless, the big data technology landscape has advanced, with newer frameworks such as Apache Spark gaining favor due to improved performance and user-friendly features.
However, the current state of Hadoop seems to be pretty promising. Numbers say that it reflects remarkable growth, with the market rising from $74.6 billion to $104.95 billion in 2023 at a compelling CAGR of 40.7%. Particularly in Europe, America, Africa, the Middle East, and Asia-Pacific, Hadoop’s popularity is wide across industries like IT, Media, Healthcare, BFSI, Government, Transportation, and Resources.
Will Apache Spark replace Hadoop, then?
At its core, Spark cannot replace Hadoop because it is not intended as a substitute but complements it. While Spark excels in areas where Hadoop MapReduce has limitations, such as handling iterative algorithms and interactive data mining with in-memory storage, it is designed to work alongside Hadoop within its ecosystem. Spark offers benefits like faster data processing and versatility, but it serves as a complementary tool rather than a replacement for Hadoop.
What is the future of Hadoop?
While Hadoop may not maintain the same level of importance, its fundamental principles will stay effective. The future of Hadoop and the Big Data Analytics market is expected to witness a robust CAGR of 23.9%, reaching an estimated $84.14 billion by 2028. The technology is poised to create 11.5 million employment opportunities globally in areas such as data science and data analytics by 2026.
Hadoop is likely to remain a good choice for large enterprises that are already familiar with its technology, and it will still be needed in industries like education or banking.
- In the educational industry, big data, facilitated by Hadoop, is used for digital education through Learning Management Systems (LMS) and monitoring students’ overall progress.
- In finance and banking, Hadoop is instrumental in addressing compliance trials, credit risk reporting, card fraud detection, and financial analytics. It also improves security measures, detects fraudulent activities, and transforms customer data for insightful analysis.
Despite its limitations, some companies may find value in Hadoop’s reliability and the trust they have developed in using it over time. The existing knowledge and infrastructure in these large enterprises can contribute to Hadoop’s continued relevance for their specific data processing needs.