Recommendation Engine Solution With Embedding-Based Retrieval Approach
Under NDA
 We Stand With Ukraine
We Stand With Ukraine 
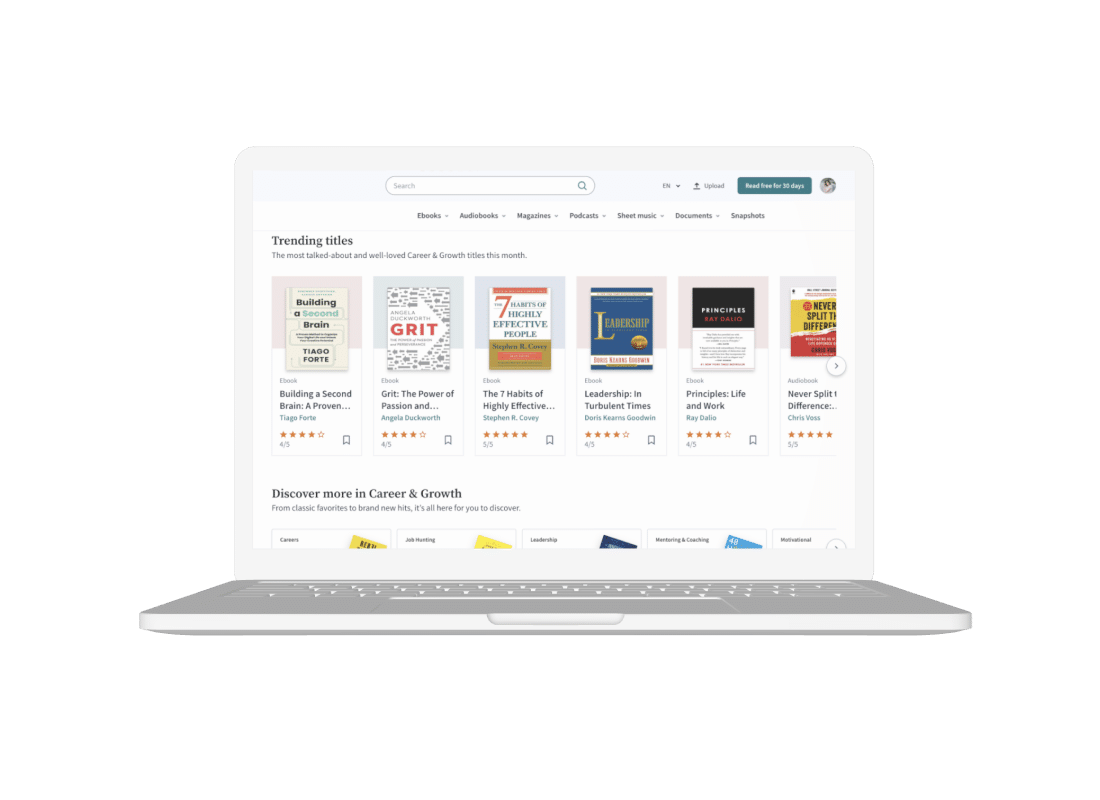
The project is a subscription service that provides users access to various books, audiobooks, news and magazine articles, documents, and more. With the platform, users can save their favorite titles, create collections from them, bookmark, and build their own library. The service is available on iPhone, iPad, Android Fire device, or a web browser so that you can access your titles anytime and anywhere.
Previously, KITRUM Team created an outstanding Big Data solution for the project’s Data Scientists and Analysts, allowing them to quickly process data, build effective pipelines, and work together on models that enhance customer experience. When the most valuable data processing issues were resolved, it was reasonable to work on improving Sribd’s recommendation engine.
Like many other entertainment platforms such as YouTube, Spotify, or Netflix, the platform used its recommender system to offer the most suitable content to its users. Although Sribd’s collaborative filtering model could predict what users are likely to read next, its approach limited the ability to personalize recommendations for each of them.
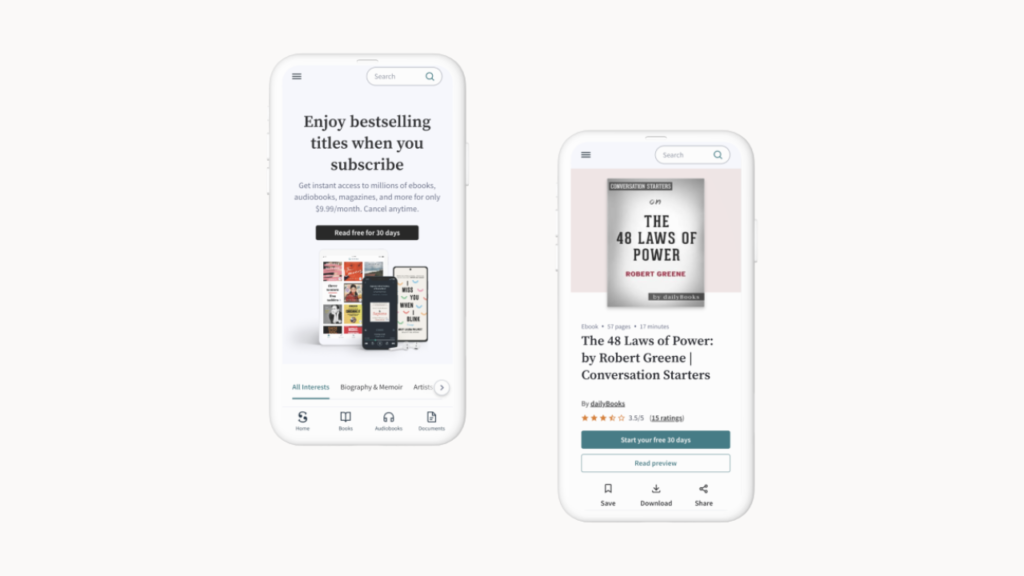
The amount and variety of content types were continuously increased, so the previous recommendation engine could not compare different content options and give an offer correctly. For example, one user was an entrepreneur and preferred to read business literature and some bestselling books such as “The Art of War” or “The 48 Laws of Power”, and the second one was a housewife who liked classic literature and romantic stories. Two different accounts here, but the system should identify their match – they both read Yoga magazines at least twice per month and are interested in healthy recipes.
There was the issue of developing a solution that would more precisely determine the content users really like, wherever it is a book, magazine, or music. To meet customer needs, KITRUM Team should integrate the most valuable machine learning multitool – vector embeddings and then deploy it on the platform.
Vector embeddings released a compact representation that stays the same size regardless of the number of data points. A model final vector, which typically contains 384 floating point values, is an exceedingly denser representation than those produced by conventional encoding techniques like one-hot encoding. It allows for keeping more information in fewer bytes, reducing utilization costs.
Machine Learning algorithms do not consume unstructured information. Thus, text or images must be converted into a numerical representation so that a model can comprehend them. Before Machine Learning, such representations were produced manually via Feature Engineering.
Since the advent of deep learning, complicated data non-linear feature interactions are learned by the model rather than manually engineered. As input cycles through a deep learning model, new representations of the input data are produced in various sizes and shapes. A unique aspect of the input is frequently the focus of each layer. Vector embeddings are created exactly by using elements of Deep Learning, which “automatically” generate feature representations from inputs.
Embeddings are notably beneficial for various ML applications since they can represent an object as a dense vector containing its semantic information.
The KITRUM team faced some technical challenges during product development:
Deploying platform to production environments
EBR data ingestion pipelines
Providing performance testing
Ensuring service-level agreement (SLA)
Support and maintenance services
These dense representations have a wide range of applications, including recommendation systems, chatbots, Q&A, and reverse image search. A quick introduction to contemporary Deep Learning models might be useful in order to grasp how vector embeddings are made.
KITRUM set up and integrated the Machine Learning platform that provides quick, reliable online recommendations to users. We applied an embedding-based retrieval approach and represented all types of platform content as vector embeddings. It allowed us to capture content semantic information while significantly facilitating its comparison process. Simply put, the content was converted to lists of numbers representing many types of data.
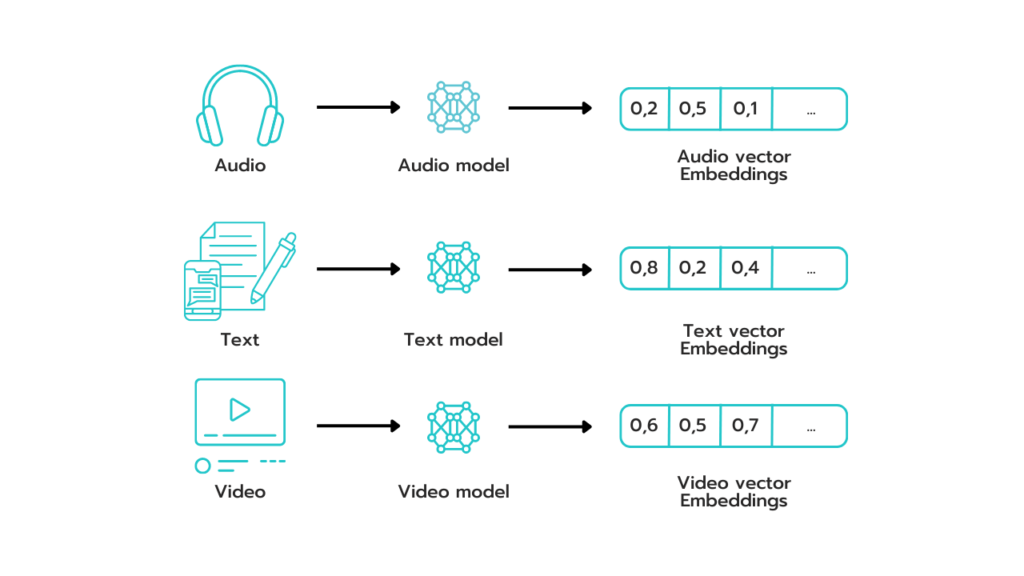
The flexibility of such a solution made it the swiss-army knife of the data scientist’s toolkit. Thereby, platform Machine Learning engineers can set up a model that predicts the next book a user will read or listen to based on what they are reading now. An embedding model will factorize the input into a vector, which will be used to predict the next type and genre of content. It literally means that similar vectors are books that are commonly read or listened to after similar books.
We also conducted load testing for our solution to ensure it could reliably handle a large number of requests per second and provide accurate recommendations. During this stage, we also tested different aspects of the system, such as dataset size, shard and replica configuration, and whatnot, to determine the effect on its performance.
The new recommendation engine is more efficient and provides its subscribers with tailored suggestions, reducing the amount of time and effort needed to find enjoyable content.
According to internal statistics, 80% of the content read or listened to on the platform is based on its recommendation system. The Solution has increased the number of users who clicked on a recommended item, enhanced their interest in offered content, and upped time for reading.
The personalization model produces recommendations for the home and discovered pages of all users who log in. It has positively affected key performance metrics, resulting in significant business growth.
“As a result, our data customers now have one place to go for their needs which has put the power of our data in their hands.”