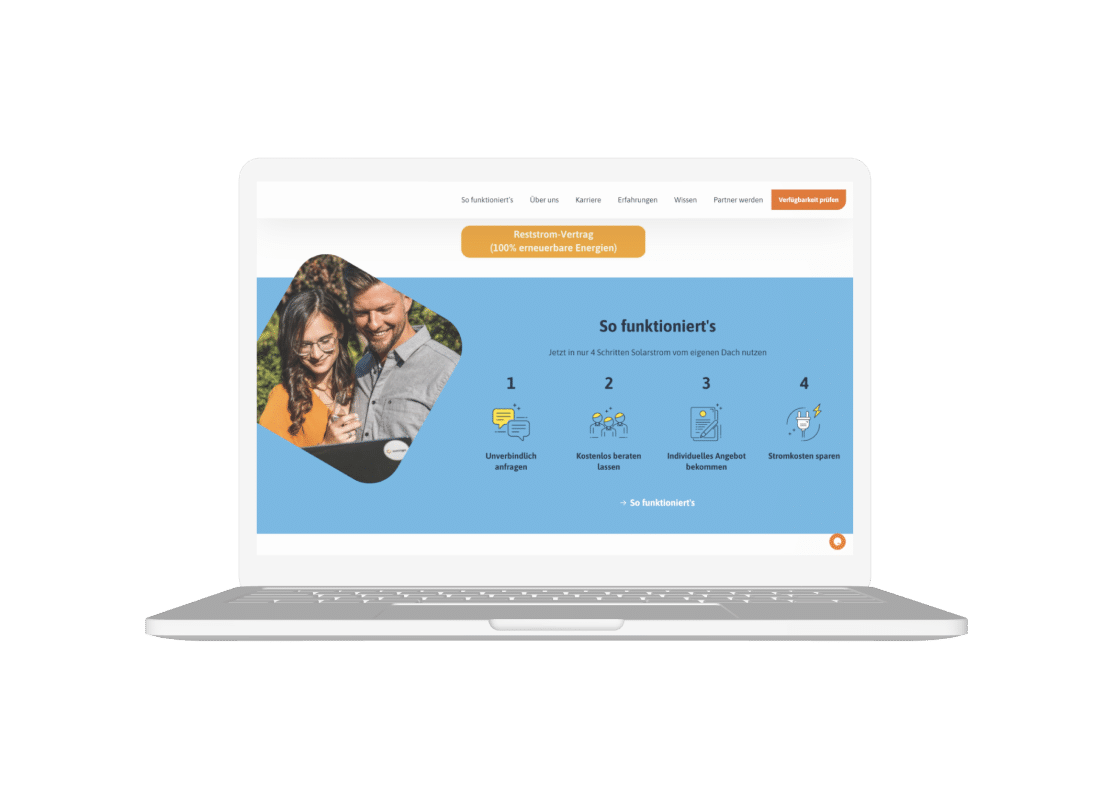
Big Data Migration From Hadoop to Databricks
Under NDA
 We Stand With Ukraine
We Stand With Ukraine 
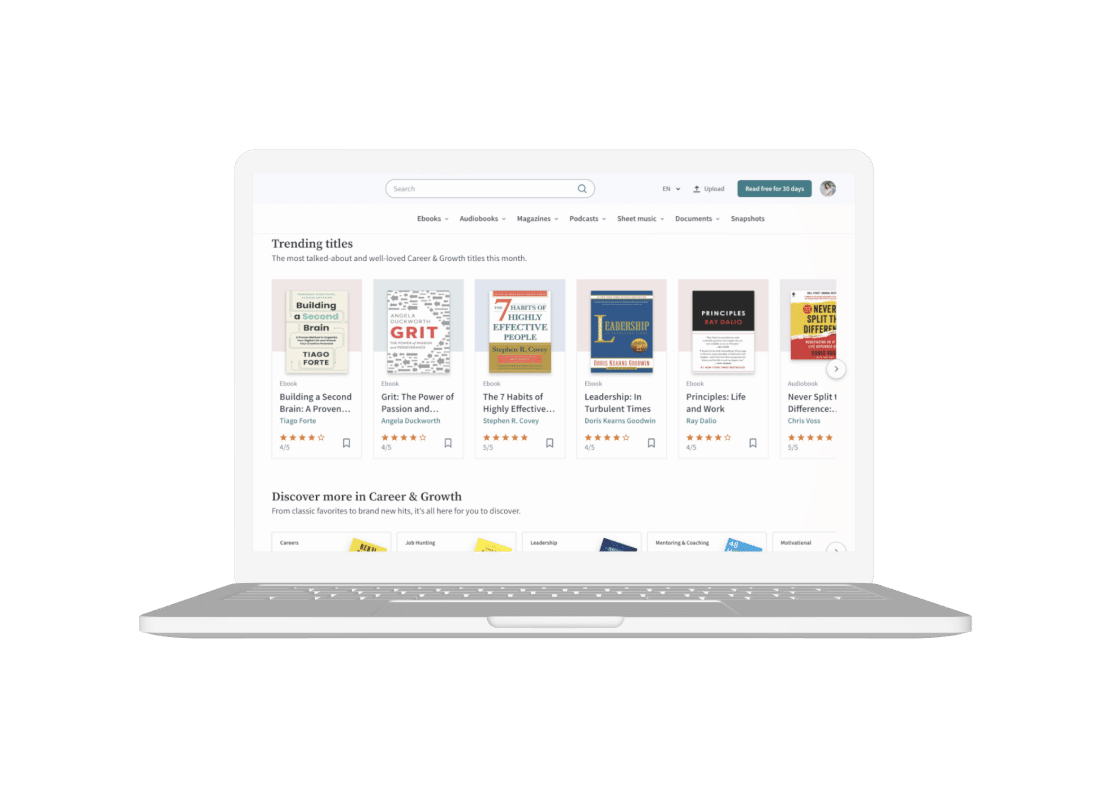
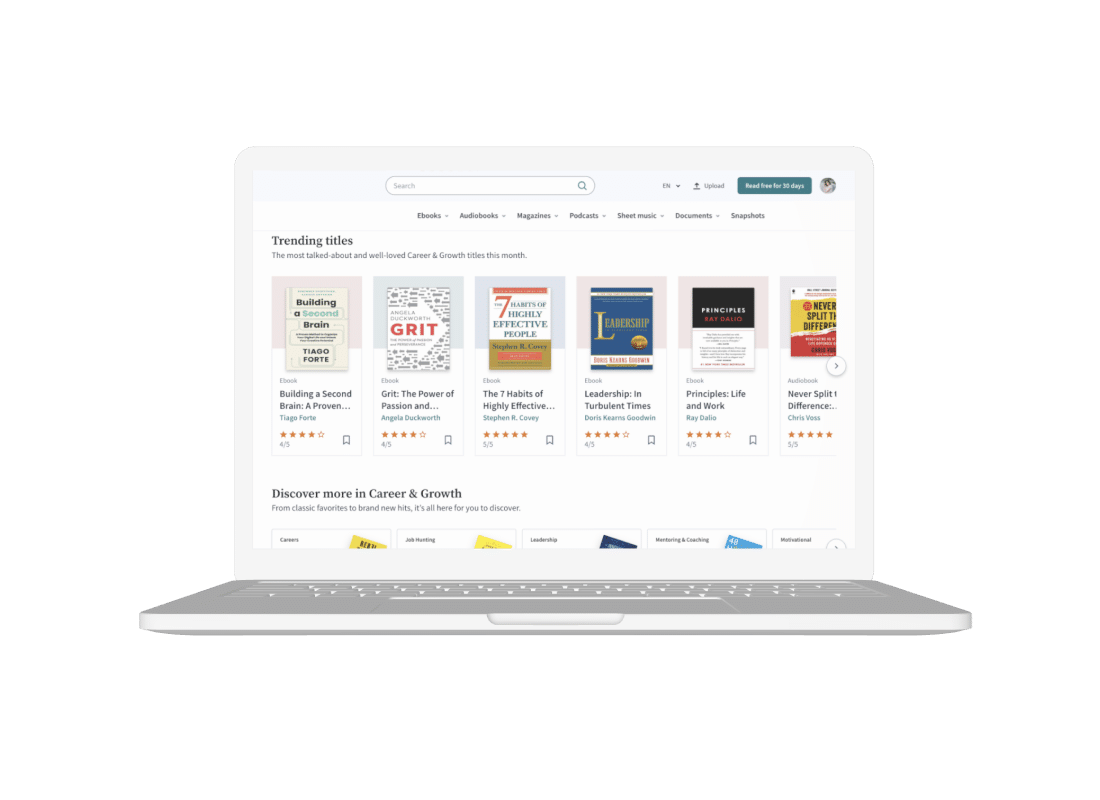
The project is an unlimited subscription service that provides access to a wide range of books, audiobooks, news and magazine articles, documents, and more. Subscribers can get millions of titles through the platform on their iPhone, iPad, Android, Fire device, or web browser. This makes it easy to access titles wherever and whenever they want. Besides, users can save their favorite titles, create collections, bookmark titles and build the library of their dreams.
The company’s mission is to “change the way the world reads.” The platform seeks to motivate readers to explore more titles available on their online platform. With millions of books accessible through the platform, they are working towards revolutionizing the way of reading.
The platform uses analytic tools and recommendation engines to help people discover the millions of titles available on its platform, encouraging its users to read without limits by providing content according to their interests.
Data is a core of the recommendation engine, and the main issue here is the inability to process the platform’s massive data sets using legacy technologies. Due to their outdated on-premises Hadoop system, Data Team faced a lack of access control to production data, difficulties with platform scalability, high support requirements, and hefty maintenance costs.
Thus, the Data Team at the company had the vision to unify and democratize their data and move it all to the cloud. As a new solution required to implement an advanced tech stack, company sought high-skilled devs to enhance its Data Team.
The involvement of an experienced team would significantly increase the effectiveness of development, improve the quality of the product, and minimize the time for platform delivery. Since the previous project’s stack had hefty maintenance costs, it was also crucial to reduce development and maintenance costs.
Developing a cutting-edge, easy-to-use, and maintained platform for Data Scientists and Data Analysts.
Providing smooth platform migration from Hadoop to Cloud solution without interrupting client’s business processes.
Ensuring platform data security while hundreds of Data specialists are working at the same time.
Achieving product conformity to the audit requirements.
Reducing maintenance costs while enhancing operational efficiency.
The main issue for most companies that use legacy systems like Hadoop is the difficulty of the data migration process to the new tech stack.
There are a few reasons, such as:
Due to our vast experience in Big Data projects, our team was ready to ensure the migration process and efficiently set and automate all internal operations of the new platform.
KITRUM fundamentally changed legacy tech stack to the following:
to unify all analytics and AI workloads in one place, benefitting both data warehouses and data lakes
to provide the foundation for storing data and tables
to allow Data specialists to build, monitor and troubleshoot pipelines with ease
So, we moved the platform to the cloud (Amazon Web Services) to take advantage of its elastic infrastructure and range of developer tools. We implemented the platform’s Lakehouse using the Databricks platform to improve development velocity and cross-team collaboration.
Provided solution decoupled compute and storage, allowing to scale each component individually. So, Apache Spark ensured quick Big Data processing and easily resolved Data Scientists and Analytics tasks.
Delta Lake facilitated building performance-optimized data pipelines that handle historical and streaming data. Any data changes are checked, audited, and approved via a custom solution built by KITRUM Team. It ensured a consistent view of data across the organization, streamlining the process of accessing and consuming data. It allowed data scientists to access their workloads easily via unified interface.
With the move to the cloud, the data team’s infrastructure complexity has been reduced, allowing for more effective and efficient operations. This solution offered better performance and scalability, which helped to create reliable data pipelines quickly and made it easier for team members to work together on models that provide an enjoyable customer experience.
Integrating cost-effective infrastructure Databricks on AWS and the AirFlow orchestrator, which has replaced a previous custom solution on Ruby, saves thousands of dollars monthly. Sure, our team did not stop there and continued our partnership with client.
We are currently working together on the optimization of a delivered platform to make it even more cost-effective. Our main task is to reduce data warehouse costs as data amounts keep growing.